Visual Semantic Relatedness Dataset for Image Captioning |
| Ahmed Sabir1, Francesc Moreno-Noguer2, Lluís Padró1 |
| Universitat Politècnica de Catalunya, TALP Research Center1 |
| Institut de Robòtica i Informàtica Industrial, CSIC-UPC2 |

|
|
|
|
Visual Semantic Relatedness Dataset for Image Captioning |
| Ahmed Sabir1, Francesc Moreno-Noguer2, Lluís Padró1 |
| Universitat Politècnica de Catalunya, TALP Research Center1 |
| Institut de Robòtica i Informàtica Industrial, CSIC-UPC2 |
|
|
|
|
Modern image captioning system relies heavily on extracting knowledge from images to capture the concept of a static story. In this paper, we propose a textual visual context dataset for captioning, in which the publicly available dataset COCO Captions (Lin et al., 2014) has been extended with information about the scene (such as objects in the image). Since this information has a textual form, it can be used to leverage any NLP task, such as text similarity or semantic relation methods, into captioning systems, either as an end-to-end training strategy or a post-processing based approach.
|
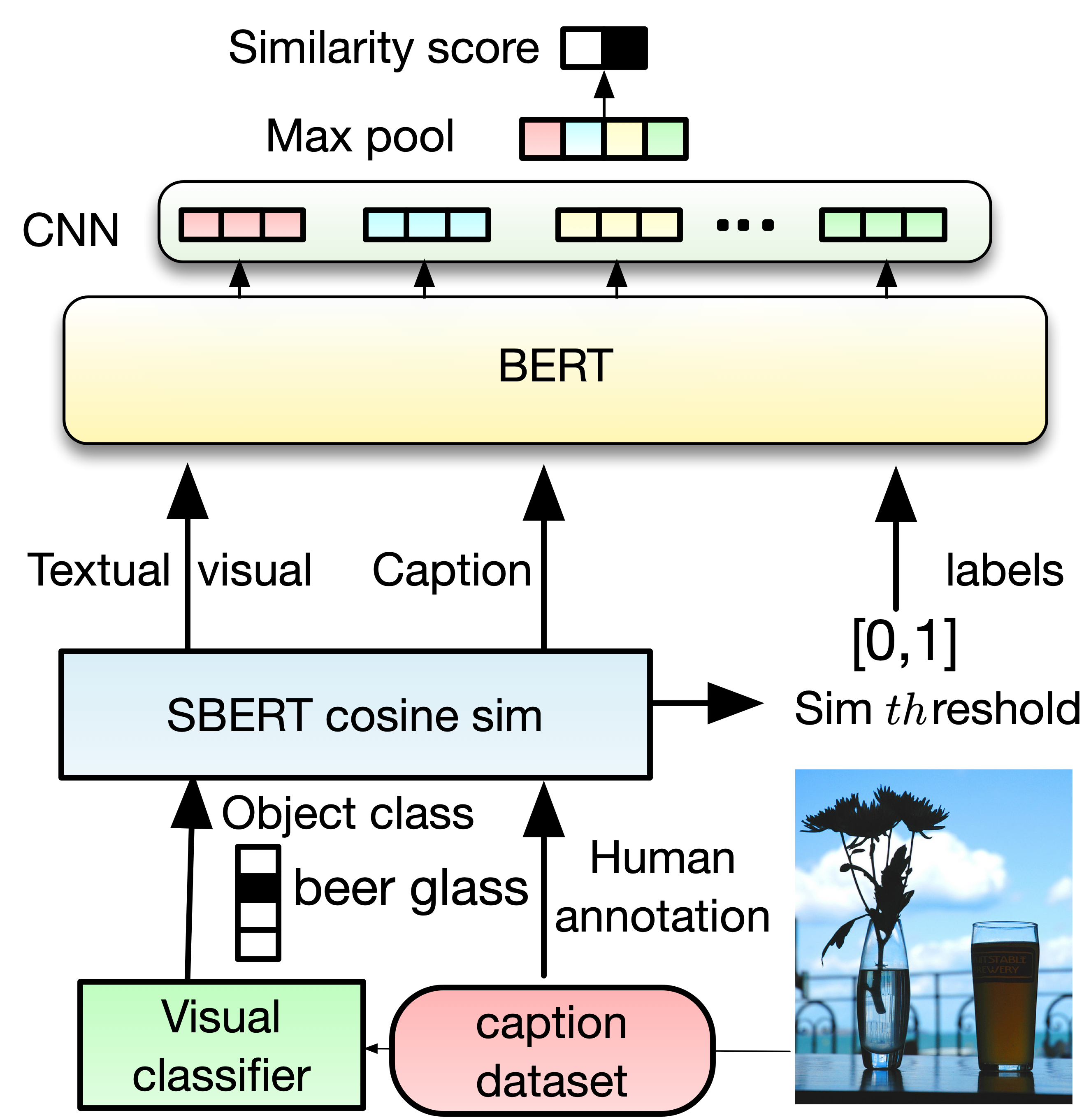
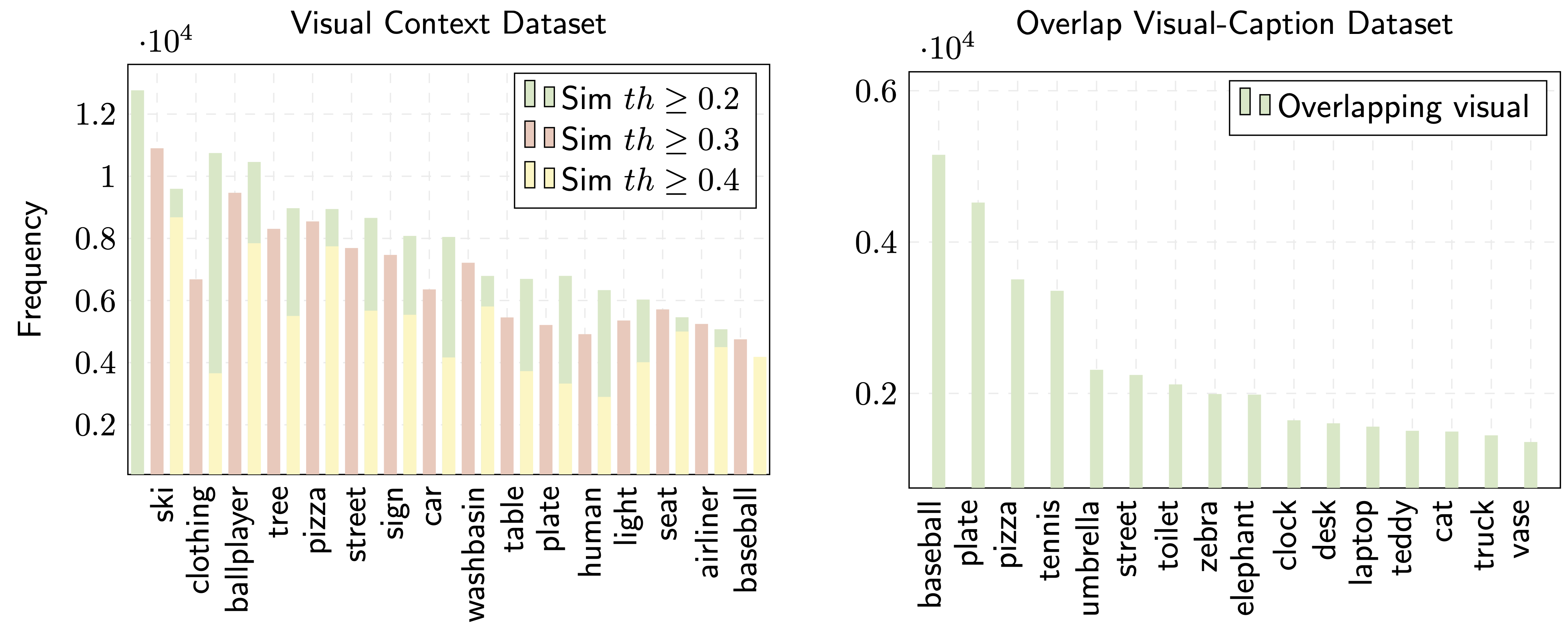
We enrich COCO Captions with textual Visual Context information. We use ResNet152, CLIP, and Faster R-CNN to extract object information for each image. We use three filter approaches to ensure the quality of the dataset (1) Threshold: to filter out predictions where the object classifier is not confident enough, and (2) semantic alignment with semantic similarity to remove duplicated objects. (3) semantic relatedness score as soft-label: to guarantee the visual context and caption have a strong relation. In particular, we use Sentence-RoBERTa via cosine similarity to give a soft score, and then we use a threshold to annotate the final label (if th ≥ 0.2, 0.3, 0.4 then 1,0). For quick start please have a look at the demo | |||||||||||||||||||||||||||||||||||||||||||||||||
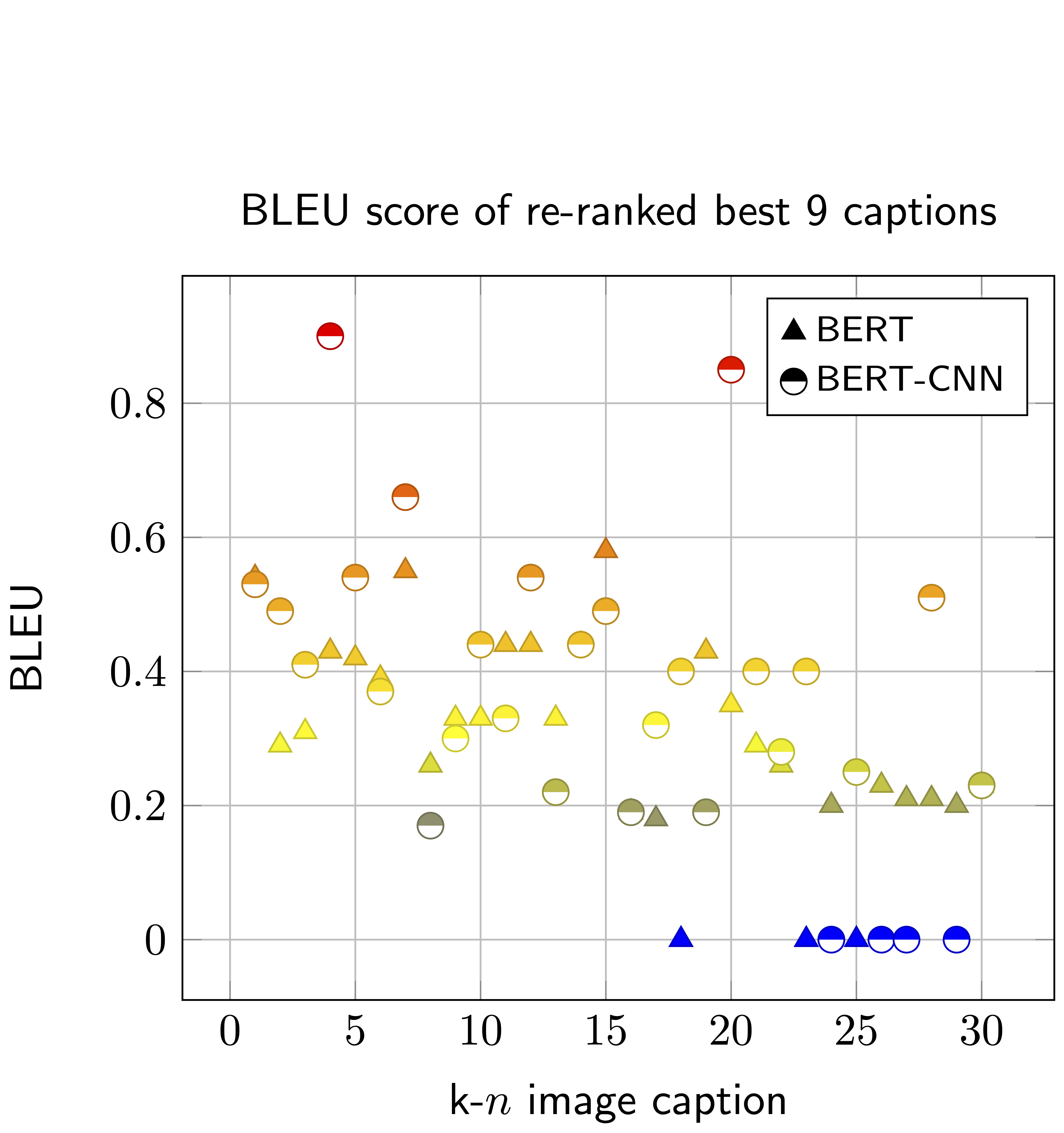
Proposed ApproachWe also propose a strategy to estimate the most closely related/not-related visual concepts using the caption description via BERT-CNN.
Resulting Dataset
We rely on COCO-Captions dataset to extract the visual context, and we propose two visual context datasets:
visual context, caption descriptions
umbrella dress human face, a woman with an umbrella near the sea.
bathtub tub, this is a bathroom with a jacuzzi shower sink and toilet.
snowplow shovel, the fire hydrant is partially buried under the snow.
desktop computer monitor, a computer with a flower as its background sits on a desk.
pitcher ballplayer, a baseball player preparing to throw the ball.
groom restaurant, a black and white picture of a centerpiece to a table at a wedding.
| |||||||||||||||||||||||||||||||||||||||||||||||||
|
OverlappingCOCO
visual context, caption descriptions, overlapping information
pole streetsign flagpole, a house that has a pole with a sign on it,{'pole'}.
stove microwave refrigerator, an older stove sits in the kitchen next to a bottle of cleaner,{'stove'}.
racket tennis ball ballplayer, a tennis player swinging a racket at a ball,{'tennis', 'racket', 'ball'}.
grocery store dining table restaurant, a table is full of different kinds of food and drinks,{'table'}.
| |||||||||||||||||||||||||||||||||||||||||||||||||
|
Another task that can benefit from the proposed dataset is investigating the contribution of the visual context to gender bias. We also propose gender neutral dataset. | |||||||||||||||||||||||||||||||||||||||||||||||||
|
Gender NeutralCOCO
visual context, caption descriptions
pizza, a person cutting a pizza with a fork and knife.
suit, a person in a suit and tie sitting with his hands between his legs.
paddle, a person riding a colorful surfboard in the water.
ballplayer, a young person in a batting stance in a baseball game.
| |||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||
|
The dataset, in most cases, has more gender-neutral person than gender bias toward men or women. However, the dataset is similar to COCO, a gender bias dataset to-ward men. |
@inproceedings{sabir2023visual,
title={Visual Semantic Relatedness Dataset for Image Captioning},
author={Sabir, Ahmed and Moreno-Noguer, Francesc and Padr{\'o}, Llu{\'\i}s},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={5597--5605},
year={2023}
}
Contact: Ahmed Sabir