Textual Visual Semantic Dataset for Text Spotting |
| Ahmed Sabir1, Francesc Moreno-Noguer2, Lluís Padró1 |
| Universitat Politècnica de Catalunya, TALP Research Center1 |
| Institut de Robòtica i Informàtica Industrial, CSIC-UPC2 |
|
|
|
|
Textual Visual Semantic Dataset for Text Spotting |
| Ahmed Sabir1, Francesc Moreno-Noguer2, Lluís Padró1 |
| Universitat Politècnica de Catalunya, TALP Research Center1 |
| Institut de Robòtica i Informàtica Industrial, CSIC-UPC2 |
|
|
|
|
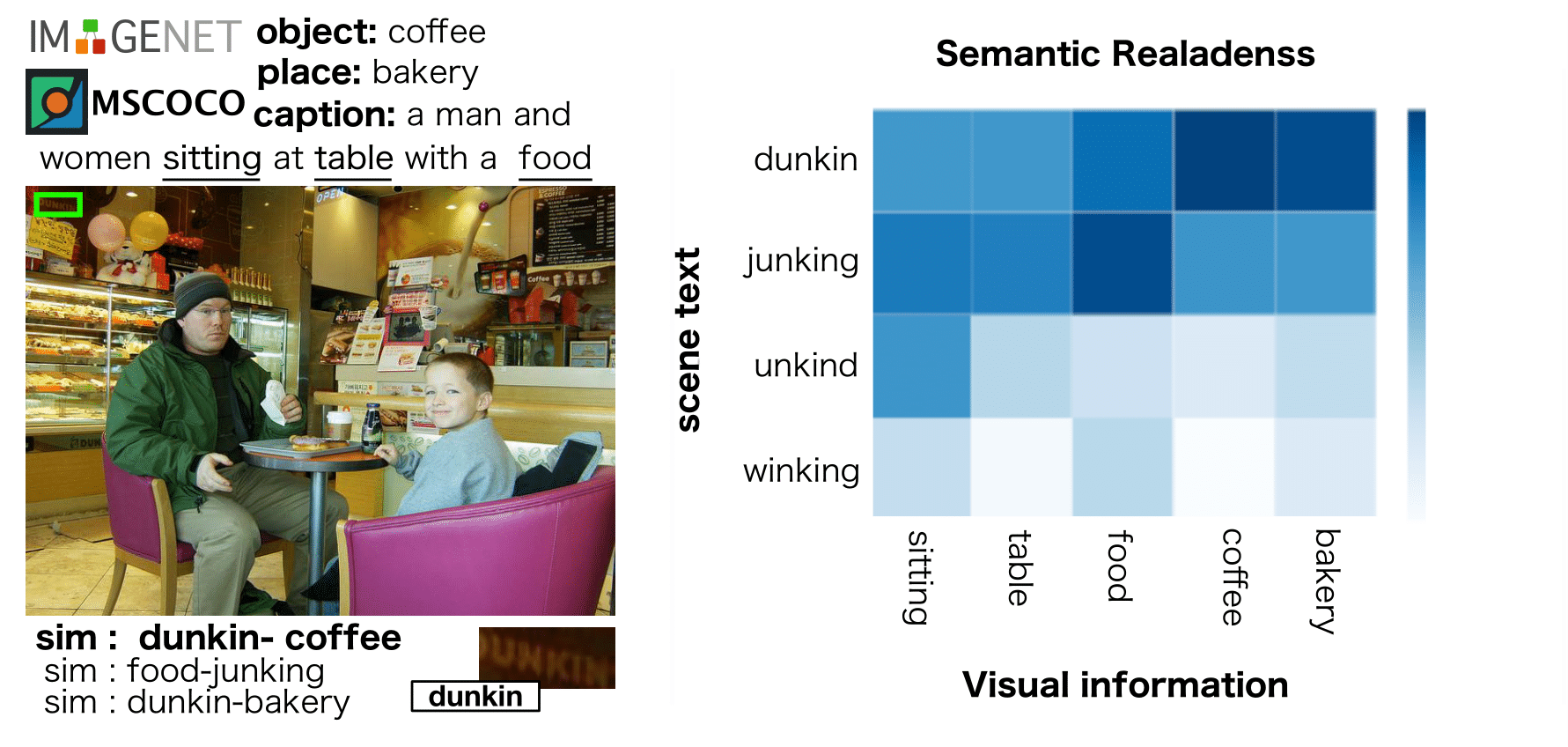
Text Spotting in the wild consists of detecting and recognizing text appearing in images (e.g., signboards, traffic signals or brands in clothing or objects). This is a challenging problem due to the complexity of the context where texts appear (uneven backgrounds, shading, occlusions, perspective distortions, etc.). Only a few approaches try to exploit the relation between text and its surrounding environment to better recognize text in the scene. In this paper, we propose a visual context dataset for Text Spotting in the wild,where the publicly available dataset COCO-text (Veit al., 2016) has been extended with information about the scene (such as objects and places appearing in the image) to enable researchers to include semantic relations between texts andscene in their Text Spotting systems, and to offer a common framework for such approaches. For each text in an image, we extract three kinds of context information: objects in the scene, image location label and a textual image description (caption). We use state-of-the-art out-of-the-box available tools to extract this additional information. Since this information has textual form, it can be used to leverage text similarity or semantic relation methods into Text Spotting systems, either as a post-processing or in an end-to-end training strategy
|
We have proposed a dataset that extends COCO-text with visual context information, that we believe useful for the text spotting problem. In contrast to the most recent method (Prasad al., 2018) that relies on limited classes of context objects anduses a complex architecture to extract visual information,our approach utilizes out-of-the-box state-of-the-art tools.Therefore, the dataset annotation will be improved in thefuture as better systems become available. This dataset can be used to leverage semantic relation between image con-text and candidate texts into text spotting systems, either as post-processing or end-to-end training. We also use our dataset to train/tune an evaluate existing semantic similarity systems when applied to the task of re-ranking text hypothesis produced by a text spotting baseline, showing that it canimprove the accuracy of the original baseline between 2 and3 points. Note that there’s a lot of room for improvement upto 7.4 points in a benchmark dataset. |
DatasetWe proposed three different types of visual context object, scene, and caption.
word, objects, places
airfrance,airliner,airfield
2010,microwave,utility room
kefalotyri,radio,storage room
stop,canoe,playground
l-17,wing,heliport
gree,street,skyscraper
|
|
with CaptionCOCO-Text-V
label, word, caption
1,parking,a street sign with a sign on the side of it
1,chase,a man is playing tennis on a tennis court (e.g., tennis sponsor)
0,sq,a small child is sitting on a couch with a laptop
1,paper,a desk with a laptop and a mouse on it
1,3,a parking meter with a parking meter on it
0,ie,a woman holding a pink umbrella in her hand
|
|
TestICDAR17-Task3-V
word, caption
pizza, a person cutting a pizza with a fork and knife
suit, a person in a suit and tie sitting with his hands between his legs.
paddle, a person riding a colorful surfboard in the water.
|
|
Object-and-text-Co-OccCOCO-Pairs
word,visual
stop, street
cable, remote
airways, airliner
4, volleyball
food, broccoli
|
@inproceedings{sabir2020textual,
title={Textual visual semantic dataset for text spotting},
author={Sabir, Ahmed and Moreno-Noguer, Francesc and Padr{\'o}, Llu{\'\i}s},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
pages={542--543},
year={2020}
}
Contact: Ahmed Sabir
